Greater Phoenix does not want technology companies. It wants companies in semiconductors, microelectronics, and advanced silicon manufacturing. That distinction matters — not just for messaging, but for identifying the right pipeline in the first place.
The challenge is that most company intelligence databases were not built for that level of precision. They were built around fixed taxonomies: Technology, Life Sciences, Financial Services, Advanced Manufacturing. Categories broad enough to be comprehensive. Too broad to be useful for economic developers who have made a deliberate, specific bet on a corner of the market.
The taxonomy burden lands on the wrong team
When a conventional database imposes its own sector taxonomy, the translation work falls to the EDO. You know exactly what you want — companies in your specific target sectors, with active expansion intent, planning to enter your market. But to surface that pipeline from a fixed-category database, you have to reverse-engineer which of their labels contains your targets. “Technology” contains cybersecurity companies, EdTech platforms, SaaS businesses, semiconductor fabs, and AI startups. You pay for the data access, then spend half a day filtering out the 90% that are irrelevant to your specific proposition.
The problem is not unique to one database. When we mapped the priority sector lists of 17 Economic Development Organisations attending SelectUSA 2026 against each other, we found 97 unique sector labels — across just 17 organisations, in one country, focused on innovation and inward investment. “Life Sciences” alone appears as eight distinct labels: Life Sciences, Healthcare & Life Sciences, BioSciences, Bioscience & Pharma, Life Sciences & Biotechnology, and more.

No conventional database taxonomy can serve all of these simultaneously without forcing each team to do the translation work themselves. The database speaks one language. Your sector strategy speaks another.
When the translation fails, the wrong companies get the wrong message
The practical consequence is diffusion. When outreach pipelines are populated by broad database categories rather than specific sector fit, teams end up contacting companies that are irrelevant to their offer. A FinTech company planning UK expansion receives a briefing deck designed for a Life Sciences audience — because both were drawn from the same “Technology” bucket. The company ignores it. The relationship opportunity closes before it opens.
For EDOs with specific, well-articulated sector propositions, diffuse outreach is not just inefficient. It undermines the credibility of the message itself. Inward investment is a relationship-driven process. Reaching the right company with a precisely relevant proposition is what creates the conditions for a conversation. A broadly targeted campaign signals that you have not done the work to understand which companies actually belong in your pipeline.
A different approach: mapping to your language
We do not have a fixed taxonomy. Our database of over 4,800 innovation companies with active expansion intent is classified against the language companies use to describe themselves — the terms they use when they are searching for investors or expansion partners. This gives us a flexible base that can be mapped to your sector language, not the other way round.
When we applied this to Maryland’s priority sectors for SelectUSA 2026 — AI, Life Sciences, Cybersecurity, Advanced Manufacturing, Aerospace, Defence, and Quantum — we found 912 companies from our US-bound cohort of 2,150 that aligned directly to at least one priority sector. That is a qualified, sector-specific pipeline, built from Maryland’s own language, without Maryland’s team having to translate a single category.
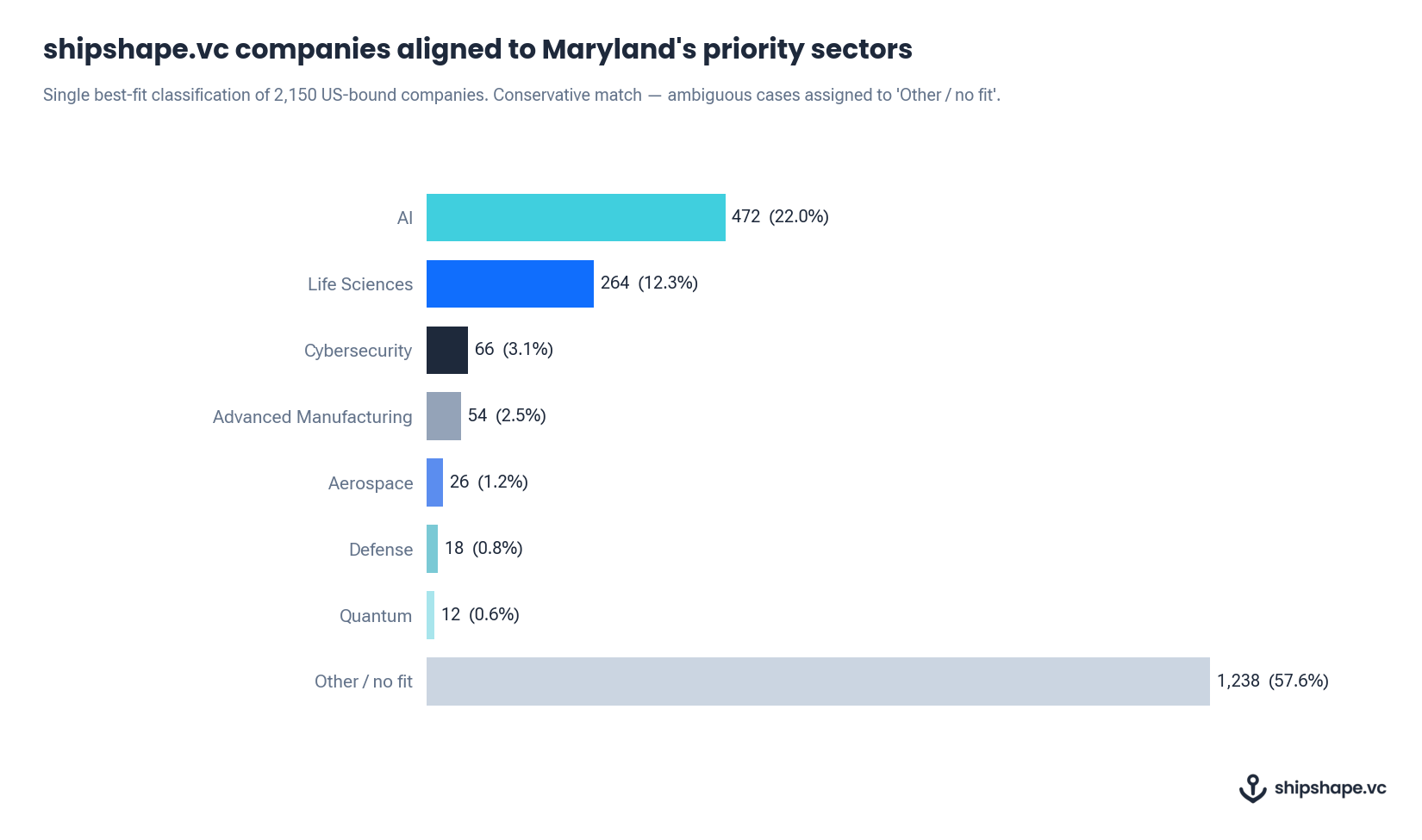
The 57.6% in Other / no fit is not a problem with the data. It is the data working correctly. Maryland does not want 2,150 companies — it wants the 912 that fit its sectors. A fixed-taxonomy database would have no mechanism to make that distinction cleanly, because its categories were not written in Maryland’s language.
Where our data comes from
Our platform tracks innovation companies actively signalling expansion intent. For each company, we hold their self-declared search phrases — the terms they use to describe their own sector — alongside declared target markets, funding stage, and team size. The 2,150 US-bound companies referenced here are from a snapshot taken in April 2026 of our global cohort of 4,803. Sector alignment to EDO priority lists is produced by mapping company search phrases against each EDO’s stated sector language, with ambiguous cases conservatively assigned to Other / no fit.
Want to see what proportion of companies planning US expansion fit your taxonomy?
Tell us your priority sectors below — in your own language, exactly as you would use them in a briefing — and we will map our pipeline against them. You will receive a breakdown by sector and a call to walk through the findings in detail.
Request your bespoke sector breakdown
Takes two minutes. You will receive a sector-mapped report and a 30-minute discovery call.